
Python is a popular and effective option for web scraping store location data from Target.com owing to its superior handling of HTTP requests and better methods for extracting data from JSON strings. Also, Python has a robust mechanism for handling errors while parsing HTML.
Python comes with many Third-party libraries that can perform web scraping from target.com, parse text, and interact with HTML. For instance, Urlib3 HTTP client library, BeautifulSoup HTML parser, Mechanical Soup API for web scraping, Requests for scraping with HTTP requests, Selenium, etc. This makes Python a popular option for web scraping store locations from target.com.
This article details how to use Python to scrape store locations from any Target.com
Why Python for Web Scraping Target Store Locations?
Python’s unique features make it a go-to programming language for web scraping of specialized tasks like scraping store location data. For instance, Python’s dynamic typing eliminates the need to define data types for variables. This results in faster coding and task completion. Python can identify variable data with its classes. Python has one of the most extensive third-party libraries that can be used for various data extraction tasks.
These third-party libraries have features for making web scraping easy and error-free:
- Perform HTTP requests programmatically.
- SSL verification, connection pooling, and proxying.
- Extract tags, meta titles, and attributes.
- Robust error handling.
- Simulates human behavior.
- Handle cookies, authentication.
- Automate web browsers.
- Automating repetitive tasks.
- Storing data in various formats.
When it comes to syntax, Python has one of the shortest code needs. With a few lines of code, you can get store location data from target websites.
Updated Dataset Available
Get the Most Recent Target Store Locations Across the USA
How Does Python-based Web Scraping of Target Store Locations Work?
Web scraping of store locations involves the use of Python-based tools to extract store location data from Target.com
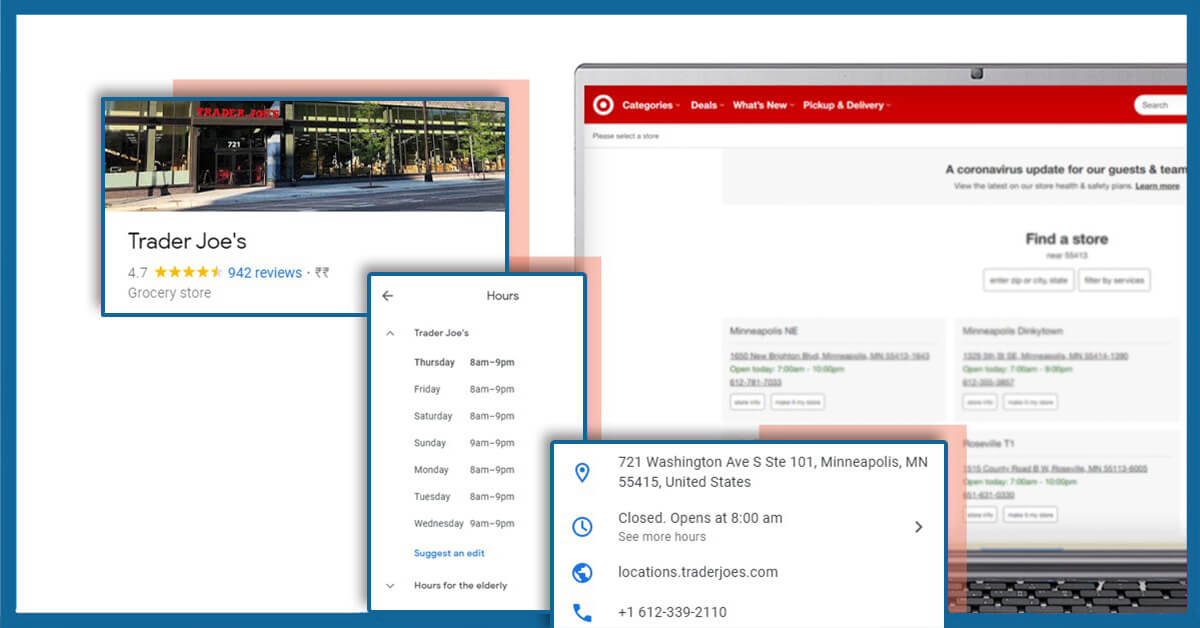
Data Fields that Can be Extracted from Store Location Data:
- Store Name
- Contact Details
- Weekday
- Address
- Store Rating
- Store Category
- Store Reviews
- Open Hours
- Store ID
- Stock Ticker
- Direction URL
- Email Address
- Latitude
- Longitude
- Service Categories
- Store Description
- Store Services
- Store Amenities
The process typically consists of the following components:
Web Crawler (Spider):
A web crawler browses the internet to search for the required content. It serves as the initial stage in the web scraping process by locating and retrieving relevant information from web pages.
Web Scraper:
The web scraper efficiently extracts data from the target websites.
Steps for Scrape Target Store Location Data
- Find the URL: Identify the specific URL containing the relevant data for your project.
- Inspect the Page: Understand the structure of the webpage and inspect the HTML format.
- Write the Code: Develop a Python code to extract the required data specifics from the webpage.
- Store the Data: Save the extracted data in the desired file format such as CSV, XML, or JSON for further analysis and use.
For instance, in the context of scraping Target store locations, Python can be used to build a web scraper that extracts essential store details such as store name, ID, address, and distance from a given zip code. The code involves the utilization of libraries such as Selenium, and Pandas, to enable command-line argument access and data extraction from the Target website.
Simplified Process for Scraping Target.com Store Locations Using Python
1. Construct the URL: Replace the URL for Target with the URL for Target for the desired location, for example, Tampa, West.
2. Download HTML: Use Python Requests to download the HTML content of the search result page.
3. Save Data: Save the downloaded data to a JSON file for further use.
Requirements
Download and Install Python 3 and Pip. Follow the installation guide for Python 3 based on your operating system (Linux, Mac, or Windows).
Install Packages
- Use Pip to install the following packages in Python:
(https://pip.pypa.io/en/stable/installing/)
- Python Requests for making requests and downloading HTML content.
( http://docs.python-requests.org/en/master/user/install/)
- UnicodeCSV package (output file will have Unicode Characters). Install it using pip install unicodecsv.
4. The Code: Use the provided Python 3 code to extract Target store locations. Ensure the code is saved in a .py file for execution (.py is a program or script written in Python).
Python Script
import requests
from bs4 import BeautifulSoup
def extract_store_data(store_url):
response = requests.get(store_url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting store details
store_details = {}
store_details["County"] = "Tampa"
store_details["Store_Name"] = "Target Department Store"
store_details["State"] = "Florida"
store_details["Street"] = soup.find('span', {'class': 'address-line1'}).text.strip() + ", " + soup.find('span', {'class': 'locality'}).text.strip()
store_details["Contact"] = soup.find('a', {'class': 'store-phone'}).text.strip()
store_details["City"] = "Hillsborough"
store_details["Country"] = "United States"
store_details["Zipcode"] = soup.find('span', {'class': 'postal-code'}).text.strip()# Extracting store timings
store_details["Stores_Open"] = ["Monday-Friday", "Saturday", "Sunday"]
store_details["Timings"] = []
hours_section = soup.find_all('div', {'class': 'hours-list-item'})
for day_section in hours_section:
day = day_section.find('span', {'class': 'day'}).text.strip()
hours = day_section.find('span', {'class': 'hours'}).text.strip()
store_details["Timings"].append({"Week Day": day, "Open Hours": hours})
return store_details
# Define the store URL
store_url = ''https://www.target.com/sl/tampa-west/2289'
# Extract and print store data
store_data = extract_store_data(store_url)
print(store_data)
Note: This script uses the requests library to fetch the HTML content of the Target store page and BeautifulSoup to parse the HTML and extract relevant store information.
5. Running the Scraper: Run the scraper script with the desired zip code as an argument to find the stores near the specified location.
usage: target.py [-h] zipcode
positional arguments:
zipcode Zip code
optional arguments:
-h, –help message and exit
For example, to find all the Target stores in and near Tampa, Florida, run the script with the zip code as the argument: ‘python target.py 33635’. This code should work for extracting details of Target stores for all zip codes available on Target.com.
6. Output: The script will create a JSON output file in the same folder as the script, containing store details such as name, address, contact, timings, etc.
{
"County": "Tampa West",
"Store_Name": "Target Department Store",
"State": "Florida",
"Street": "11627 W Hillsborough Ave, Tampa",
"Stores_Open": [
"Monday-Friday",
"Saturday",
"Sunday"
],
"Contact": "+1 813-749-5961",
"City": "Hillsborough",
"Country": "United States",
"Zipcode": "33635",
"Timings": [
{
"Week Day": "Monday-Friday",
"Open Hours": "8:00 a.m.-10:00 p.m."
},
{
"Week Day": "Saturday",
"Open Hours": "8:00 a.m.-10:00 p.m."
},
{
"Week Day": "Sunday",
"Open Hours": "8:00 a.m.-9:00 p.m."
}
]
}Conclusion
Python proves to be an effective and versatile tool for web scraping store location data from Target.com. By following the steps outlined in this post, you can extract store location data from any target.com.
However, if you find the technical aspects of using Python challenging, there are alternatives available. You can obtain readymade store location data from on-demand data providers like LocationsCloud. We provide up-to-date location datasets without the need for coding expertise.

